
목차
UTF-8 BOM 이란 무엇인가
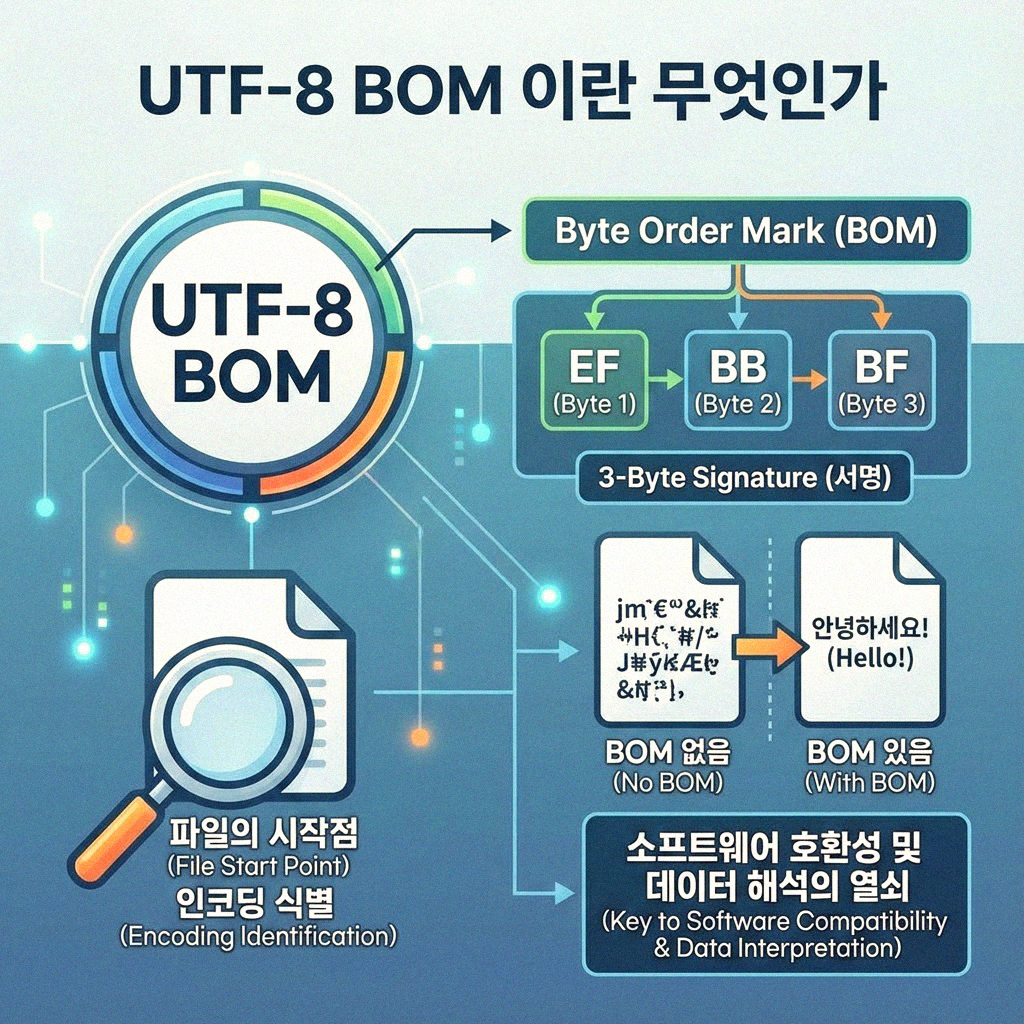
텍스트 파일을 다룰 때 종종 마주치는 'UTF-8 BOM'은 파일의 시작 부분에 포함될 수 있는 특별한 문자열입니다. BOM은 Byte Order Mark의 약자로, 파일 인코딩을 명시적으로 나타내는 역할을 합니다. UTF-8 인코딩의 경우, BOM은 파일이 UTF-8로 저장되었음을 알리는 용도로 사용됩니다. 하지만 이 BOM 문자는 일반적인 텍스트 데이터로 간주되지 않아, 파일 읽기 시 예상치 못한 문제를 일으킬 수 있습니다. 특히 C#의 StreamReader를 사용하여 파일을 읽을 때, BOM이 존재하면 파일 내용의 시작 부분에 원치 않는 문자열이 추가되거나, 올바르게 파일을 인식하지 못하는 경우가 발생할 수 있습니다. 따라서 텍스트 파일을 처리할 때는 이러한 BOM을 제거하는 과정이 필수적입니다.
BOM은 주로 Windows 환경에서 생성된 텍스트 파일에서 흔히 발견됩니다. UTF-8 BOM은 `EF BB BF`라는 세 바이트로 구성되며, 파일의 맨 앞에 위치합니다. 이 문자가 있을 때와 없을 때, 텍스트 편집기나 프로그램의 파일 해석 방식에 차이가 발생할 수 있어 주의가 필요합니다.
| 구분 | 설명 |
|---|---|
| BOM | Byte Order Mark. 파일의 인코딩 방식을 명시합니다. |
| UTF-8 BOM | UTF-8 인코딩 파일임을 나타내는 3바이트의 특수 문자 (EF BB BF). |
| 발생 문제 | StreamReader에서 BOM을 텍스트로 잘못 인식하여 파일 내용에 영향을 줄 수 있습니다. |
StreamReader 에서 BOM을 제거하는 방법
C#의 StreamReader 클래스는 파일을 읽을 때 BOM을 자동으로 처리하는 기능을 제공합니다. 바로 StreamReader 생성자에서 detectEncodingFromByteOrderMarks 매개변수를 활용하는 것입니다. 이 매개변수에 `true`를 전달하면, StreamReader는 파일 시작 부분에서 BOM을 감지하고 자동으로 제거하여 읽어들입니다. 이는 가장 간편하고 권장되는 방법입니다. 별도의 로직 없이 StreamReader 자체의 기능을 통해 BOM 문제를 해결할 수 있다는 장점이 있습니다.
하지만 특정 상황에서는 BOM을 명시적으로 제거해야 할 필요가 있을 수도 있습니다. 예를 들어, BOM이 존재하지 않아야 하는 환경에서 파일을 생성하거나, BOM이 포함된 파일을 다루면서도 BOM 자체를 제어해야 할 때가 그렇습니다. 이럴 때는 파일의 첫 세 바이트를 읽어 BOM이 있다면 건너뛰는 로직을 직접 구현해야 합니다.
핵심 포인트: `StreamReader`의 `detectEncodingFromByteOrderMarks` 옵션을 `true`로 설정하는 것이 BOM 제거의 가장 쉽고 효과적인 방법입니다.
▶ 기본 사용법 (BOM 자동 감지):using (StreamReader sr = new StreamReader("yourfile.txt", Encoding.UTF8, true))
▶ BOM을 명시적으로 제거하는 로직 (고급):
이 방법은 조금 더 복잡하며, 일반적으로는 기본 사용법으로 충분합니다.

직접 BOM 제거 로직 구현하기
앞서 설명한 `detectEncodingFromByteOrderMarks` 옵션으로 해결되지 않거나, BOM 자체를 직접 제어하고 싶을 때 사용할 수 있는 방법입니다. 파일 스트림을 열고, 첫 세 바이트를 읽어 UTF-8 BOM(`0xEF`, `0xBB`, `0xBF`)인지 확인합니다. 만약 BOM이 존재한다면, 스트림의 위치를 세 바이트만큼 앞으로 이동시켜 BOM을 건너뛴 후, 나머지 데이터를 `StreamReader`로 읽어들이는 방식입니다. 이 로직을 구현하면 BOM 유무에 상관없이 파일 내용을 일관되게 처리할 수 있습니다. StreamReader 생성 시 인코딩을 명시적으로 UTF-8로 지정하는 것이 중요하며, BOM이 감지되었을 경우를 대비하여 `true`가 아닌 `false`로 설정하거나, 인코딩을 따로 지정하지 않아도 됩니다.
이 방식은 조금 더 저수준의 파일 처리 방식을 사용하므로, 파일 입출력에 대한 이해가 필요합니다. 그러나 일단 구현해두면 다양한 파일 형식이나 인코딩 문제를 해결하는 데 유용하게 활용될 수 있습니다.
▶ 직접 BOM 제거 로직 (예시): using (FileStream fs = new FileStream("yourfile.txt", FileMode.Open, FileAccess.Read))
using (StreamReader sr = new StreamReader(fs, Encoding.UTF8, false))
{
if (fs.Length >= 3) {
byte[] bom = new byte[3];
fs.Read(bom, 0, 3);
if (bom[0] != 0xEF || bom[1] != 0xBB || bom[2] != 0xBF) {
fs.Seek(-3, SeekOrigin.Current); // BOM이 아니면 이전 위치로 되돌림
}
}
string content = sr.ReadToEnd();
// content 사용
}
| 방법 | 장점 | 단점 |
|---|---|---|
| StreamReader 옵션 활용 | 간단하고 편리함, 별도 코드 불필요 | BOM 존재 시에만 동작 |
| 직접 BOM 제거 로직 | BOM 유무를 직접 제어 가능, 복잡한 파일 처리 가능 | 구현이 다소 복잡함, 코드 추가 필요 |

StreamReader UTF-8 BOM 제거를 위한 코드 구현
UTF-8 BOM(Byte Order Mark)은 파일의 인코딩 방식을 알려주는 특수 문자입니다. 하지만 텍스트 파일 처리 시 이 BOM 문자가 예상치 못한 문제를 일으키는 경우가 종종 있습니다. 특히 StreamReader를 사용하여 파일을 읽을 때, BOM이 포함되어 있다면 의도치 않은 문자가 문자열 앞에 붙어버릴 수 있습니다. 이를 해결하기 위해 StreamReader에서 UTF-8 BOM을 제거하는 로직을 직접 구현하는 것은 매우 유용합니다. 이 과정은 파일 내용을 올바르게 파싱하고 처리하는 데 필수적입니다.
가장 일반적인 방법은 파일을 읽기 전에 BOM을 확인하고, 만약 존재한다면 이를 건너뛰고 나머지 데이터를 읽는 방식입니다. C#에서는 `StreamReader`의 `CurrentEncoding` 속성을 활용하거나, 파일을 바이트 배열로 읽어 BOM을 직접 판단하는 방법을 사용할 수 있습니다.
핵심은 파일의 시작 부분에 BOM이 있는지 확인하고, 있다면 해당 바이트를 건너뛰는 것입니다. 이렇게 하면 텍스트 파일의 내용을 깨끗하게 가져올 수 있습니다. StreamReader UTF-8 BOM 제거 로직은 간단하면서도 매우 효과적인 방법으로 구현될 수 있습니다.
| 구분 | 설명 |
|---|---|
| UTF-8 BOM | EF BB BF (3바이트)로 표시되며, 파일의 시작 부분을 알립니다. |
| 문제점 | StreamReader가 BOM을 자동으로 처리하지 못하면, 문자열 앞에 '?' 또는 다른 알 수 없는 문자로 표시될 수 있습니다. |
| 해결 방법 | 파일을 읽기 전에 BOM 바이트를 확인하고 건너뛰는 로직을 추가합니다. |
핵심 포인트: StreamReader에서 BOM을 제거하는 것은 파일의 무결성을 유지하고 텍스트 데이터를 정확하게 다루기 위한 필수적인 단계입니다.
실제 적용 시 주의사항 및 팁
StreamReader를 사용하여 UTF-8 BOM을 제거하는 로직을 구현할 때 몇 가지 주의사항을 염두에 두는 것이 좋습니다. 첫째, 모든 UTF-8 파일이 BOM을 가지고 있는 것은 아닙니다. BOM이 없는 파일을 BOM 제거 로직으로 처리해도 문제는 없지만, 불필요한 확인 과정을 거칠 수 있습니다. 따라서 BOM이 있을 경우에만 제거하도록 구현하는 것이 효율적입니다. 둘째, 다양한 환경에서 생성된 텍스트 파일의 인코딩은 다를 수 있습니다. UTF-8 외에 다른 인코딩(예: ANSI, EUC-KR)을 가진 파일이라면 BOM 제거 방식이 달라지거나 다른 인코딩을 명시적으로 지정해야 할 수 있습니다.
또한, 라이브러리를 활용하는 것도 좋은 방법입니다. 많은 프로그래밍 언어의 파일 처리 라이브러리는 UTF-8 BOM을 자동으로 감지하고 처리하는 기능을 내장하고 있습니다. 만약 직접 구현하는 것이 부담스럽거나 오류 발생 가능성을 줄이고 싶다면, 이러한 내장 기능을 활용하는 것을 적극 추천합니다. 텍스트 파일 인코딩 문제는 예상보다 자주 발생할 수 있으므로, 이 부분에 대한 이해는 필수적입니다.
▶ 1단계: 파일 스트림을 바이트 단위로 읽습니다.
▶ 2단계: 파일 시작 부분의 3바이트가 UTF-8 BOM(EF BB BF)인지 확인합니다.
▶ 3단계: BOM이 존재하면 해당 바이트를 건너뛰고 나머지 데이터를 읽습니다. BOM이 없으면 그대로 데이터를 읽습니다.
핵심 요약
• StreamReader에서 UTF-8 BOM은 예상치 못한 문자를 유발할 수 있습니다.
• BOM 제거 로직은 파일 시작 부분의 3바이트를 확인하여 구현합니다.
• 모든 UTF-8 파일에 BOM이 있는 것은 아니며, 라이브러리 활용도 좋은 대안입니다.
주요 질문 FAQ
Q. StreamReader에서 UTF-8 BOM이 발생하는 이유는 무엇인가요?
UTF-8 BOM(Byte Order Mark)은 파일의 인코딩이 UTF-8임을 나타내는 세 바이트의 특수 문자입니다. Windows 시스템에서는 텍스트 편집기나 프로그램이 파일을 UTF-8로 저장할 때 자동으로 BOM을 포함시키는 경우가 많습니다. StreamReader는 기본적으로 파일의 BOM을 인식하고 처리하지만, 특정 상황에서는 이를 제거하지 않고 문자열의 일부로 인식하여 예상치 못한 결과를 초래할 수 있습니다.
Q. StreamReader에서 UTF-8 BOM을 제거하는 가장 기본적인 방법은 무엇인가요?
StreamReader 생성 시 Encoding 매개변수에 `new UTF8Encoding(false)`를 사용하여 BOM이 없는 UTF-8 인코딩을 명시적으로 지정하는 것입니다. 이렇게 하면 StreamReader는 파일을 읽을 때 BOM을 자동으로 처리하지 않고, 마치 BOM이 없는 파일처럼 동작하게 됩니다.
Q. 이미 BOM이 포함된 텍스트 파일을 읽은 후에 BOM을 제거하려면 어떻게 해야 하나요?
StreamReader를 기본 설정으로 사용하여 파일을 읽은 후, 반환된 문자열의 시작 부분에 BOM이 있는지 확인하고 있다면 제거해야 합니다. UTF-8 BOM은 "\uFEFF" 문자에 해당하므로, `string.StartsWith("\uFEFF")`를 사용하여 확인하고 `string.Substring(1)` 등을 사용하여 첫 번째 문자를 제거하는 방식으로 처리할 수 있습니다.
Q. StreamReader.ReadToEnd() 메서드로 전체 파일을 읽어온 후에 BOM을 제거하는 코드 예시를 보여주세요.